

Dokumentobjektmodellen är en grundläggande del av World Wide Web. DOM för kort, det här är en uppsättning API-standarder som definierar hur en webbläsare ska konstruera ett webbdokument och hur utvecklare kan manipulera objekt.
Vi ser lite längre in hur DOM verkligen fungerar. Modellen har funnits i flera år och bor för närvarande på DOM-nivå 3 (DOM3-dokumentation här). Det finns en DOM4 för närvarande i redaktörens utkast med några helt nya specifikationer som kommer snart. För närvarande kan vi fokusera på en kort förståelse av hur objektmodellen kom fram.
En historielektion
Under de första dagarna av webbscripting var det inget standard sätt att komma åt sidobjekt. Detta gjorde det möjligt för stora webbläsare att komma in och skriva egna standarder och regler för dokumentmanipulation. Programvaruföretagen skrev även sina egna Scripting-språk som VBScript av Microsoft och Applescript av Apple.
De tidiga modellerna var mycket begränsade. Du kan bara komma åt specifika element som bilder eller forminmatningar. Med tiden utvecklade World Wide Web Consortium en standardmodell som de flesta vanliga mjukvarutgivare följde. Speciellt Microsofts Internet Explorer, Netscape, Safari och Opera.
För närvarande har DOM genomgått många ändringar och möjliggör mycket exakt manipulation av sidelement. Med skriptbibliotek som jQuery och MooTools utvecklare kan spendera mycket mindre tid på buggar.
Modern DOM Scripting idag
JavaScript är överlägset det mest populära språket bland utvecklare. Ursprungligen startat som ett open source-projekt av Netscape 1995. Det bygger på det populära programmeringsspråket Java och har modifierats av otaliga samhällen webbutvecklare.
DOM-enheten är endast användbar i situationer när objekt kan nås. För det mesta stöder alla standardkompatibla webbläsare idag alla element och metoder för DOM-manipulation i sin helhet. Med denna standardisering av objektmodellen har vi sett en ökning av enkla skript och sidfunktionalitet.
Dokumentträdet
När man tänker på DOM kan det lätt förstås i jämförelse med ett träd. När ett dokument laddar varje sidelement hålls i minnet som ett nytt objekt. Dessa kallas ibland som noder av trädet.
Som exempel bör varje korrekt HTML-sida börja med ett HTML-element och allt sidinnehåll ska laddas in i en kropp element. Det betyder att din trädhierarki börjar med ett root-HTML-element och går över till sin första nod kropp.
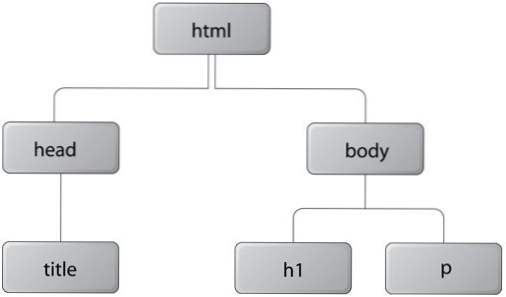
Det här är en enkel idé men det ger enorma makt till utvecklare. Från detta kan vi dra många typer av element från sidan bara genom att komma åt deras specifika nod eller plats i dokumentet. Ett litet manus kan skrivas för att dra alla bilder från en sida och trycka dem in i en matris för lagring.
Härifrån är det möjligt att komma åt varje bildelement via JavaScript. Nedan har jag lagt till en kod som anger 2 variabler. Den första håller det 3: e bildobjektet i minnet medan den andra drar src sträng från elementet.
Node Methods
När du väl har möjlighet att manipulera och få tillgång till noder kan du trycka funktioner på dem. Objektmodellen är inte bara för att korsa sidan, utan även att applicera nya effekter.
Dessa kallas metoder och de är skrivna i DOM-specifikationen. När man föreställer sig ett nodbaserat trädsystem kommer dessa metoder att rensa upp mest förvirring. Nedan är ett litet exempel på några populära metoder du kan använda på noder:
nodeA.firstChildnodeA.lastChildnodeA.parentNodenodeA.nextSiblingnodeA.prevSibling
De flesta av dessa metoder kan användas inom en variabel deklaration eller funktionsavkastning. De kommer att returnera ett objekt från DOM i förhållande till din nuvarande placering.
De första två kommer att fånga den första inre noden respektive den sista inre noden. Detta är vad sökordet barn ska representera, med nodA vara förälder till båda barnen. Detta bör också förklara hur parent fungerar som du kan dra nodobjektet som sitter direkt ovanför din nuvarande väljare.

Båda syskonfunktioner är okända för de flesta och målelementen på samma hierarkiska nivå. Som ett exempel om du krypterade en oorderad lista med 3 li taggar du bara kunde ringa nextSibling 2 gånger innan du återvänder null. Många av dessa funktioner har sedan blivit nedskalade av tredje partsbibliotek i snabbare och mer exakta metoder.
Element Klasser och ID
Ett av de mest populära sätten att hämta objektinformation är genom direkt inriktning. Om du har skrivit HTML-kod bör du veta om klass- och ID-attribut. Dessa kan ställas in på alla sidelement och är notoriskt användbara för tillämpning av CSS-format.

När du skapar dessa attribut erkänner DOM dem som separata miljöer från det övergripande dokumentet. ID-er måste vara unika bland din sida och orsaka fel i skript om du duplicerar samma namn. Klasser kan innehålla otaliga element, även om de snabbt kan sänkas ner.
Den populära metoden getElementById () har använts av utvecklare i ett decennium för att förenkla processen med objektmanipulation. Denna metod tar ett enda strängargument som håller ID-värdet för något element du vill rikta in. Som sådan kan du ändra en bild src attribut snabbt med liknande kod:
Förskott i modellen
Med release av det populära jQuery-biblioteket är det enklare än någonsin att utveckla kraftfulla skript. Äldre funktioner som getElementById () och getElementsByTagName () är fortfarande tillgängliga, även om de är avskilda av de flesta standarder.
Det snabbaste sättet att komma igång med att manipulera DOM är att nå objekt genom jQuery. Ett enkelt metodsamtal $ (Dokument) .ready ({}) Det är allt som krävs för att köra en ny händelse. De $() syntax används för att representera att dra någon typ av objekt från sidan.

Detta kan användas för att dra ID och taggar från en sida. Varje kräver helt enkelt samma symboler som används i CSS-deklarationer som $ (# Myid) och $ ('. MyClass). När du är inne i färdigfunktionen kan jQuery du dra ut så många händelser och funktioner som du behöver.
Biblioteket är optimerat för hastighet och med DOM som för närvarande utvecklas snabbt ser vi stora språng i scripting support. Varje nod laddas i en objektminneplats som både webbläsaren och utvecklaren får tillgång till.
Slutsats
Open source-rörelsen har i stor utsträckning bidragit till utvecklingen av DOM-specifikationer. Under de senaste 10 åren har vi sett XML välkomna i dokumentationen tillsammans med sätt att definiera innehållsfeeds (RSS, Atom, etc).
Det är viktigt att hålla sig på trenderna som webbutvecklare. Webben går fort och dokumentobjektmodellens senaste revisioner visar hur mycket kontroll som finns tillgänglig idag. Om du vill gräva vidare i DOM-skriptet erbjuder vi samlingar av jQuery-tricks och många webbdesign-videotutorials helt gratis!